Introduction
While there have always been good reasons to decompose large applications into small ones, the convergence of cloud services, DevOps and continuous delivery practices have made this a more desirable goal in recent years. This process is now usually described as decomposing a monolithic application into microservices.

If only this decomposition was as easy as solving a Rubik’s cube (the world record currently stands at 3.47 seconds). Of course much has been written about how to make the process easier. We’ve developed analytical tools to help: domain-driven design, looking for seams, bounded contexts, code analysis tools and much more. All of these are useful and have their place, but the question remains.
What actually happens when a developer sits down at their machine to write the code?
As a developer, I focus on the small every-day code changes that result in a successful software creation process. What I want to suggest here is an approach to software development that makes the process of breaking a monolith into microservices more productive and less risky.
The strangler fig pattern gets us only so far
A general approach for monolith to microservice migration has been defined as the Strangler Fig pattern (unfortunately often shortened to “Strangler Pattern”). Much like a strangler fig does to a host tree, we create microservices that gradually surround and replace the original monolith.
But while the Strangler Fig pattern does capture a useful approach, it’s also a high-level pattern which doesn’t tell us how to create the microservices themselves. When we’ve done our design work and the developers sit down at their machines, what happens next?
Rewriting services, and why that is a problem
Unfortunately (in my opinion) the approach most commonly taken is to rewrite services from scratch and “turn off” the related code in the monolith. This approach is attractive because it sounds less risky to build clean new services. A rewrite also allows you to start working with your new microservice DevOps tools and technologies right away. And it should be said that there are indeed valid reasons for taking the rewrite path. Here is a good summary of them.
So what’s the problem then? By choosing to rewrite services we’ve just added a lot of risk to our migration.
Why is rewriting services risky? First let’s talk about refactoring.
When it comes to software construction, we’ve come a long way in managing complexity and risk. As developers we’ve adopted practices such as unit testing, test-driven-development, and perhaps most importantly in this case, refactoring.
Refactoring (noun): a change made to the internal structure of software to make it easier to understand and cheaper to modify without changing its observable behavior.
Martin, Fowler. Refactoring (Addison-Wesley Signature Series)
The success of refactoring in managing risk is largely based on the size of the changes we make, sometimes called an atomic change, or what I like to call a move. In refactoring, each move we make is defined by a short (measure in minutes or at most a few hours) code-compile-test-commit process. When combined with trunk-based development, our overall risk is greatly reduced because:
- Developers are integrating changes rapidly.
- Code is being deployed often to production.
- When a bug is discovered there is a small set of changes that may have caused it.
The key to effective refactoring is recognizing that you go faster when you take tiny steps, the code is never broken, and you can compose those small steps into substantial changes. Remember that—and the rest is silence.
Martin, Fowler. Refactoring (Addison-Wesley Signature Series)
Finally, one important aspect of refactoring as it relates to microservice extraction is the concept of The Two Hats. Introduced by Kent Beck, the idea here is that at any given time a developer is either refactoring or adding new functionality. Because refactoring operations are so short, a developer can rapidly toggle between these two activities.
So how does this apply to rewriting services?
Let’s first talk about the use of the term refactoring in discussing a microservice rewrite. “Atomic change” and “refactoring” are often used when describing the rewriting of a single microservice, but in general this is a misuse of these terms.
Even if an effort is made to reduce the scope of the change by focusing on small or “edge” services, the duration of such a change is usually measured in weeks or months. It’s impossible to benefit from the risk-reduction of refactoring with such large scale changes.
Let’s take a high-level look at what this type of microservice rewrite looks like. To begin with, here’s a simplified graphic of what’s undoubtedly a very complex monolith.
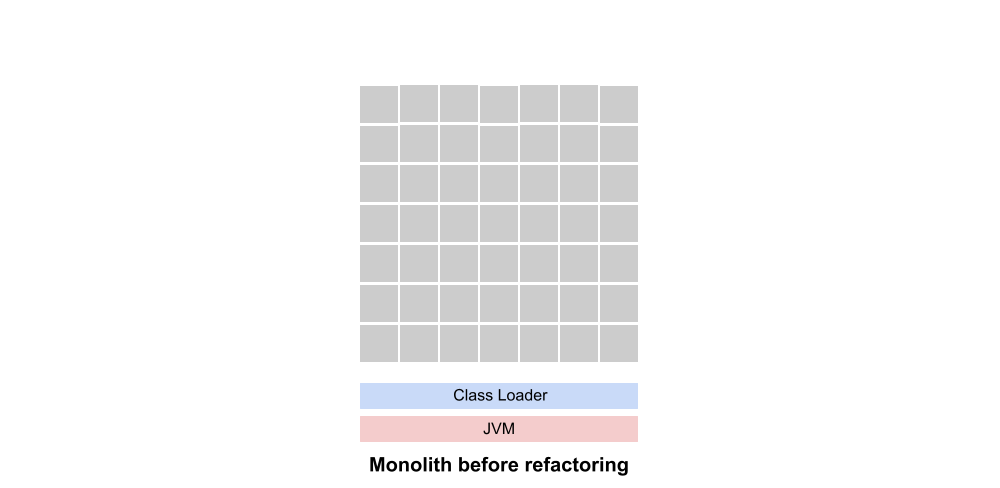
More than likely the code representing our new microservice is scattered throughout the monolith. Otherwise an extraction through refactoring would be a simple matter.
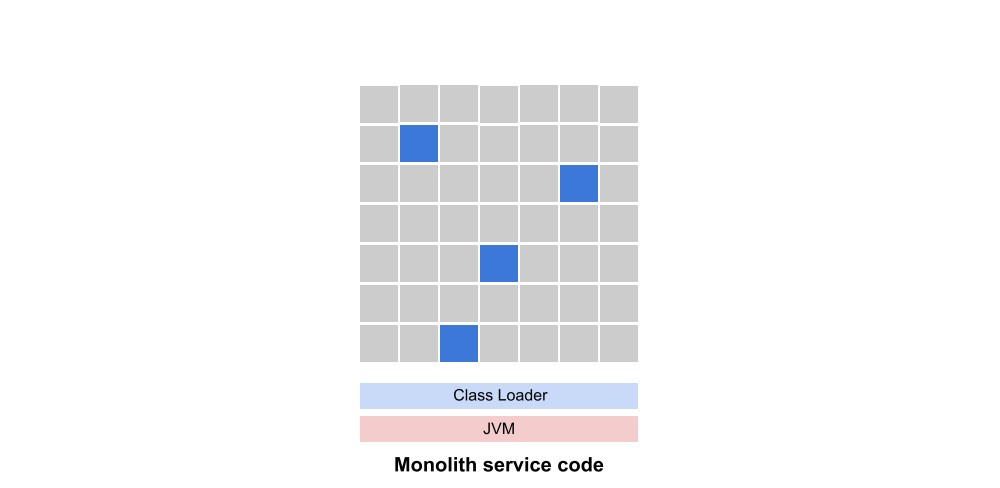
If the choice is made to rewrite the service, developers will iteratively create the new microservice over a period of weeks or months. During this time only the monolith is in production.
When the new microservice is ready to be released to production, an attempt is usually made to manage risk by running the two versions of the service in parallel, gradually shifting from the monolith implementation to the new remotely-deployed microservice.
Eventually, the implementation in the monolith is “retired” and the dead code is either removed or left in place. Here’s an animated gif that show the outlines of the process.
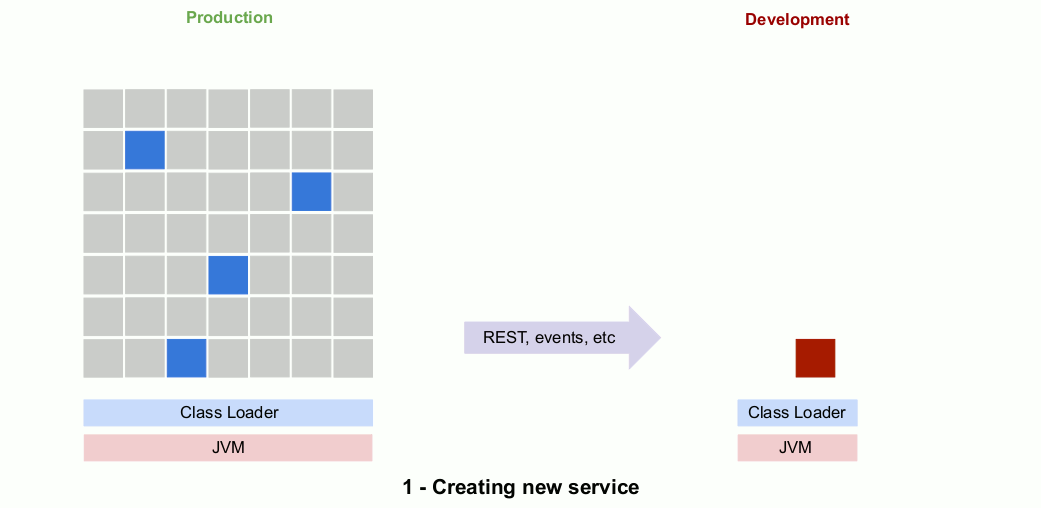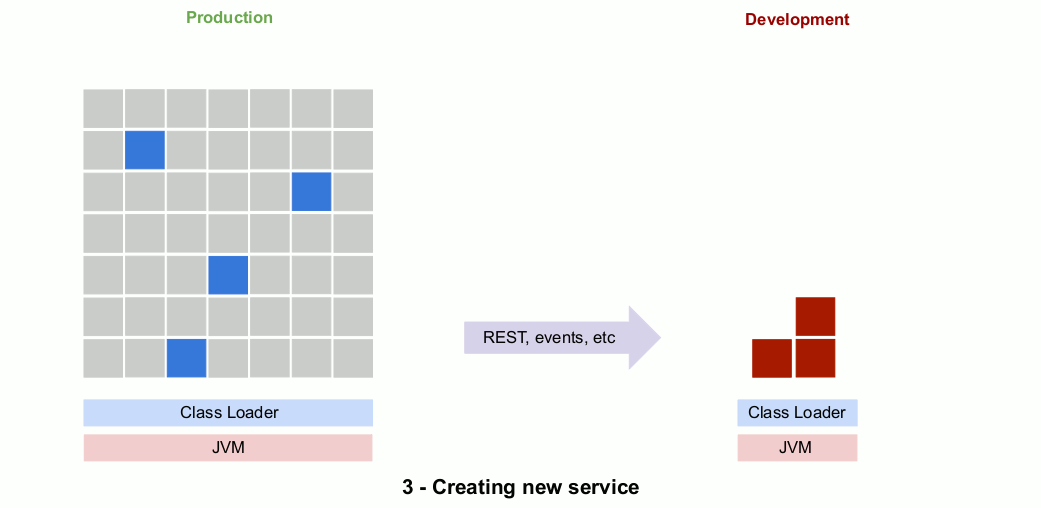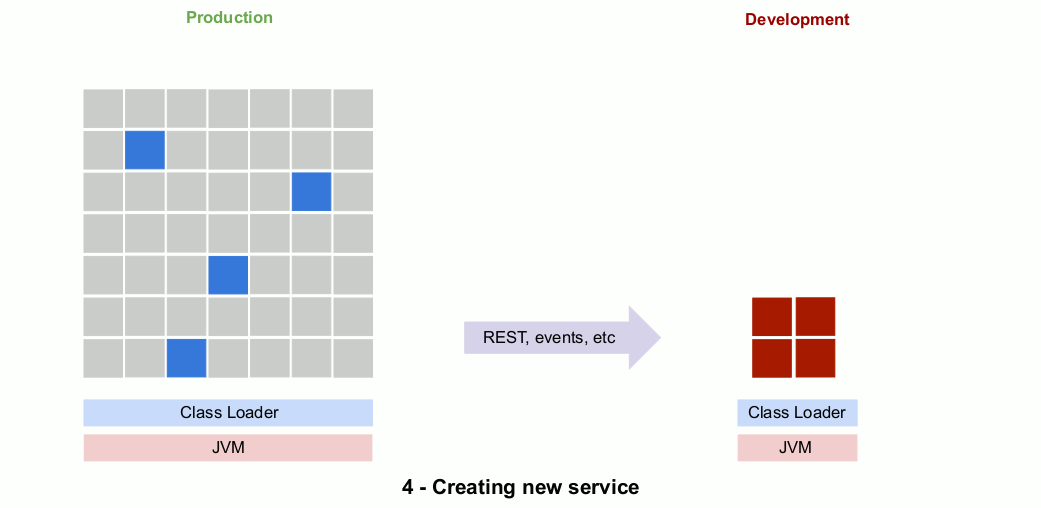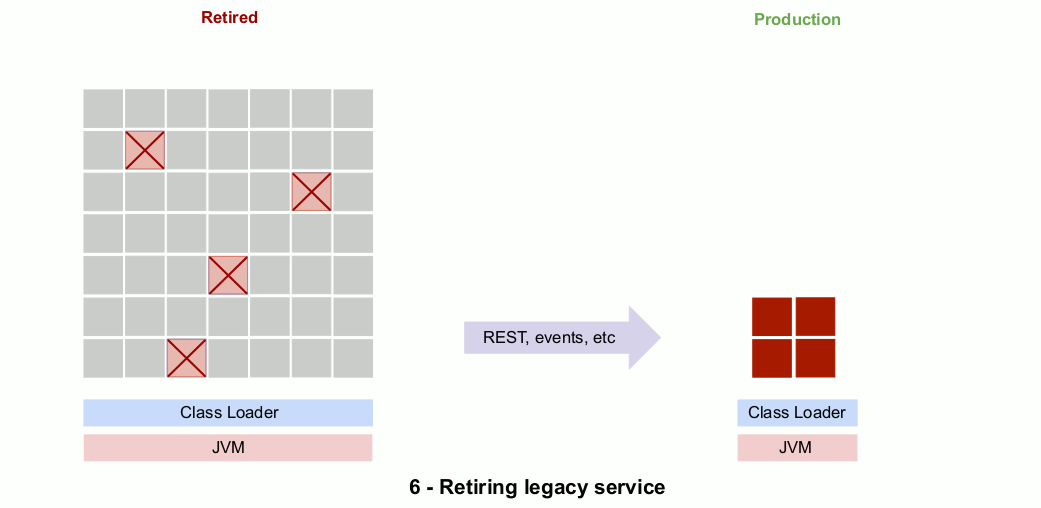
So why is this risky?
- First and most obviously, the new microservice code has not been rigorously vetted through multiple small-scale releases to production. The entire microservice is deployed in one large move and when things go wrong it can be extremely difficult to track down exactly where the problem is.
- Second, we are combining the release of new microservice code with an entirely new runtime environment involving remote communication (REST, events, etc.), containerization, and cloud-based deployment. Releasing a new service on it’s own would be risky enough, but combining these two elements at the same time more than doubles your risk.
- Finally, during the duration of the rewrite it is difficult change or add features to the service. If there is a requirement for a feature change or addition during this period you’ll need to decide whether to do this in the new microservice only (making end-users wait) or to make a parallel change in the monolith as well (which adds risk).
So what is the solution?
Extracting a service through fine-grained refactoring
A better approach is to treat the extraction of a microservice from a monolith as the long-term (weeks or months) target of a series of fine-grained refactoring operations (minutes or hours).
Because the gradually evolving code is continuously deployed to production, we are greatly reducing the risk of complex bugs. Because the refactoring operations are short, we can mix feature changes and new feature development into the process. To be more explicit, in this approach the microservice extraction itself is not viewed as a refactoring operation. We should welcome new feature development while the extraction is underway.
Another benefit to this approach is that the API of the new microservice is allowed to evolve gradually as the refactoring operations occur. Doing a full rewrite of the service requires us to take a guess at what the API should be. Only when we fully integrate the new service with the monolith do we find out how successful we were.
Finally, because the microservice is only deployed remotely after the extraction is complete, we are separating the risk of creating the microservice from the risk of changing the runtime environment. We know the new microservice works, so the problems that arise in changing the runtime stack are much easier to track down.
So why isn’t this done more often. Well I don’t want to underestimate the difficulty of this type of refactoring. Part of the solution is learning how to practice refactoring properly. Also, having good unit test coverage and practicing solid TDD are not easy as well.
But I think the biggest issue is tooling. With standard Java IDE tooling a developer is usually attempting to migrate code into a new Java package or perhaps a new project that will be deployed as a separate JAR file on the monolith class path. But the feedback (compiler warnings, etc.) and automatic refactoring operations we have are not sufficient when faced with the complexity of this type of extraction. One solution is to bring in static code analysis and dependency analysis tools, but the outputs of these tools can be a challenge to incorporate into a tight refactoring loop.
So what would it take to apply true refactoring operations to the monolith to microservices migration? My suggestion is that modular tooling and techniques have much to offer and can make this process possible if not necessarily easy.
Introducing modular tooling
When discussing modular tooling and techniques, I’m specifically talking about OSGi and the open-source Eclipse tooling built around it – either the Plug-in Development Environment or BndTools. It’s also possible this could be done with the Java Platform Module System and related tooling.
For our purposes, a module system such as OSGi is a container that sits on top of the JVM and provides true class loader separation between JARs (what OSGi calls bundles). JARs running under OSGi or JPMS are also allowed to selectively export functionality at the Java package level, allowing us to truly encapsulate code just as we have always done with class member (e.g. private and protected methods).

The Eclipse tooling built around OSGi (including a specialized compiler) allows developers to create JAR-level encapsulation and see the effects of that encapsulation in real time. The tooling also allows developers to use normal refactoring techniques backed by the extra information provided by the OSGi compiler.
Here are the specific steps that I would recommend for extracting a microservice from a monolith using modular tooling and techniques.
Step 1: Wrap your monolith as a module using OSGi (or JPMS if you prefer)
While this may sound complicated, converting a monolith into a single OSGi bundle is relatively straightforward. It basically requires us to bring all the monolith code into one project (including third-party libraries) and then add a small text-file (MANIFEST.MF) describing which packages are visible outside of the bundle.
Because OSGi creates a class loader for each JAR, the monolith will usually run without issues inside the OSGi container. After all, being a monolith it was probably expecting a single class loader to begin with. Most frameworks (IoC, DI, Spring, etc.) are also usually expecting a single class loader and will run fine.
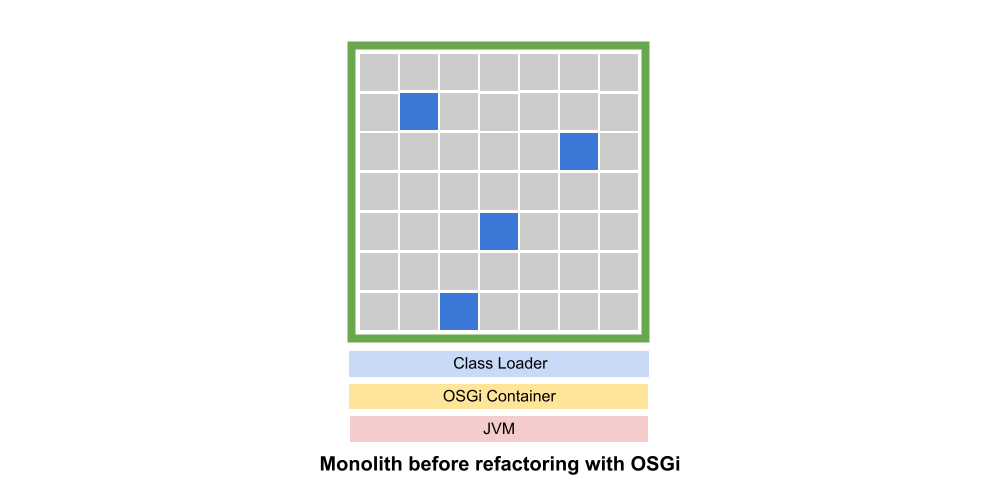
At this point we’ll also lock down the JAR, meaning that no monolith packages are exported. This provides compiler support for the idea that no external microservice should have any dependencies on the monolith.
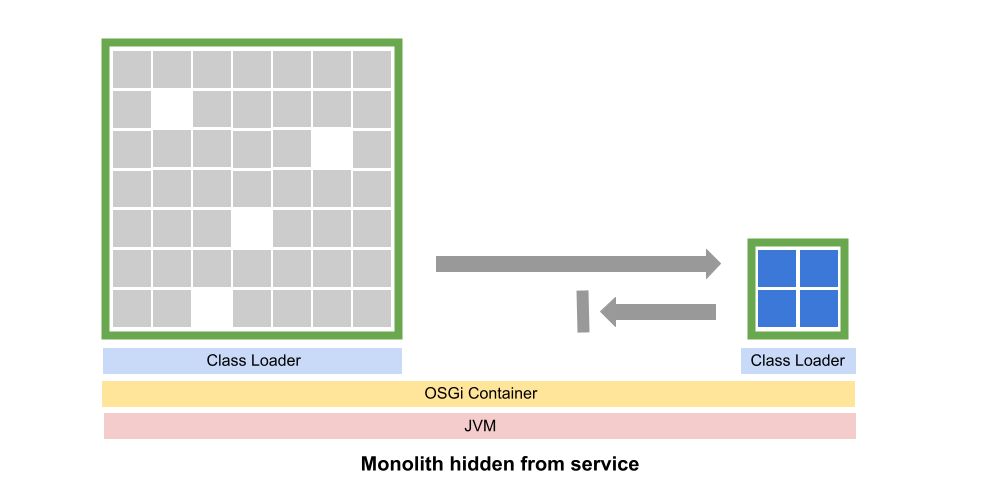
Step 2: Use fine-grained refactoring practices to extract the microservice
The next step is to apply tight, iterative, refactoring loops through which we gradually extract the microservice from the monolith. We start by creating a second project deployed as a JAR and containing OSGi metadata. As developers move code from the monolith to the microservice JAR, the OSGi compiler is providing modular context and IDE-supported refactoring operations.
These small refactoring operations, supported by unit testing, allow for regular commits and deployments. Essentially the microservice is evolving in a second JAR that will eventually be deployed remotely. But in the meantime the microservice can be deployed regularly as a JAR file as part of the monolith.
Also, in the microservice we can separate out the service API and implementation into separate packages. Then we can use OSGi metadata to export only the API package, giving developers the compiler and runtime feedback to confidently perform refactoring operations.
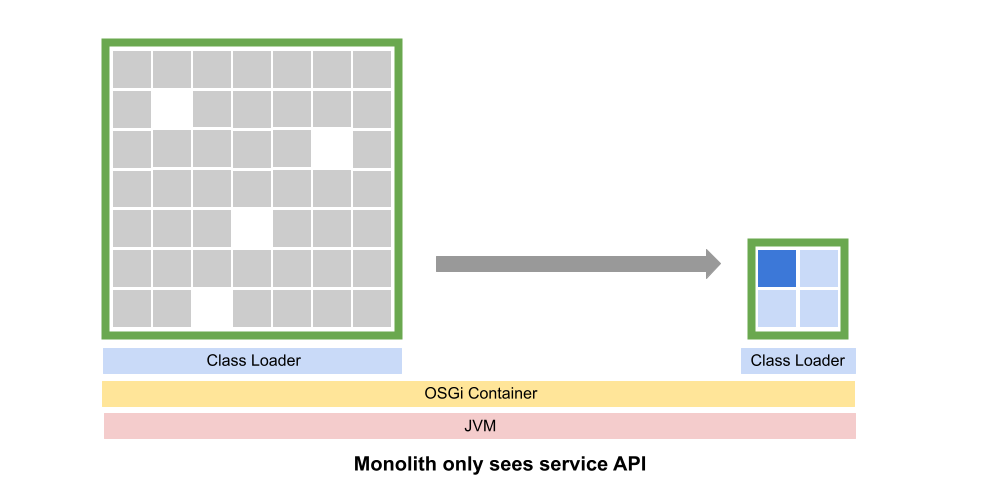
This animated gif shows what the process would appear like to a developer. Inside the IDE the application appears as two OSGi bundles and runs inside of an OSGi container. Code is gradually refactored in a process that might take weeks or months, but that still adheres to CI/CD best practices.
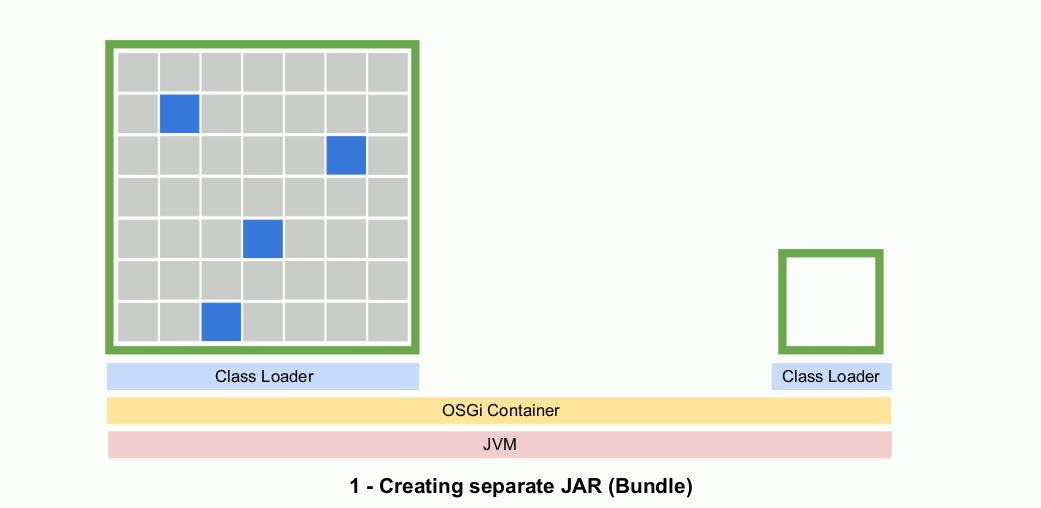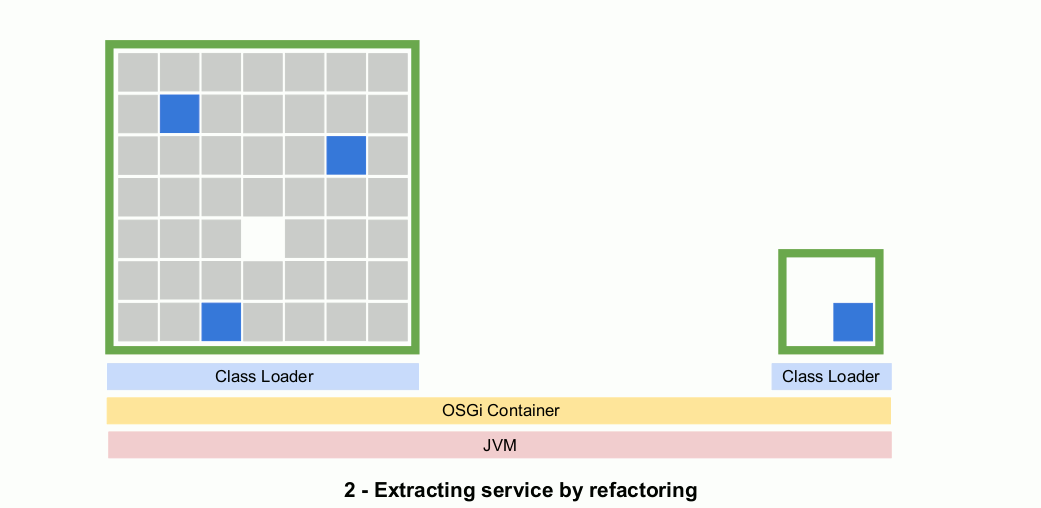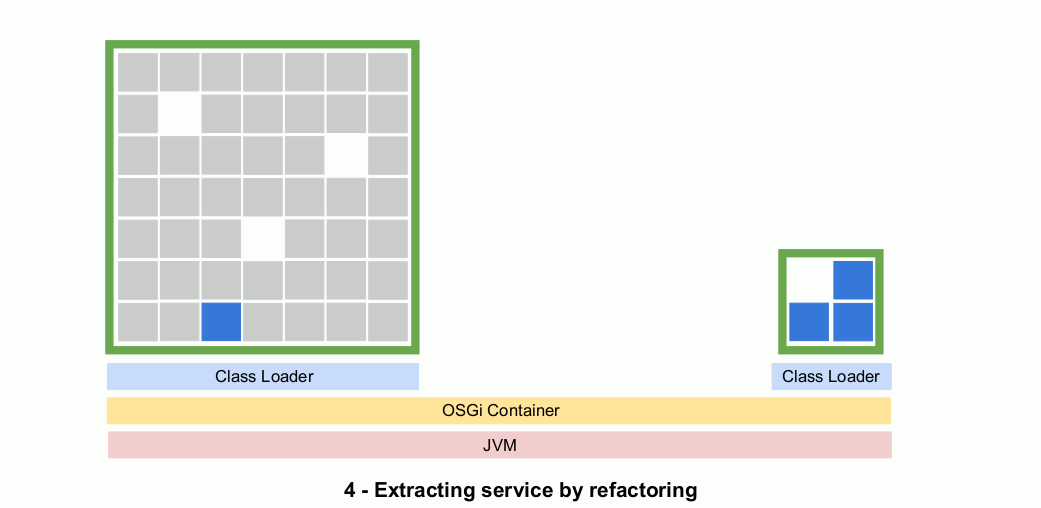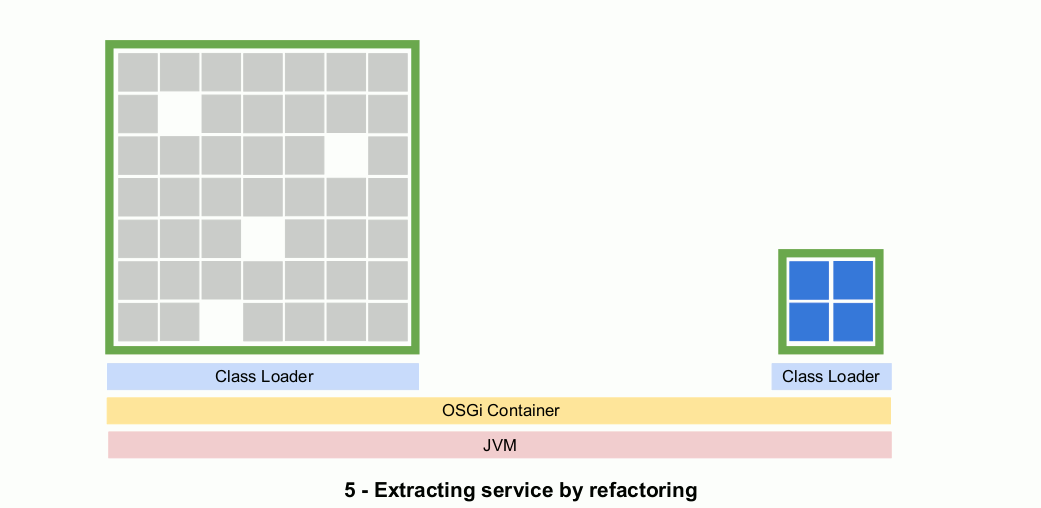
Step 3: Deploy as often as you like while refactoring
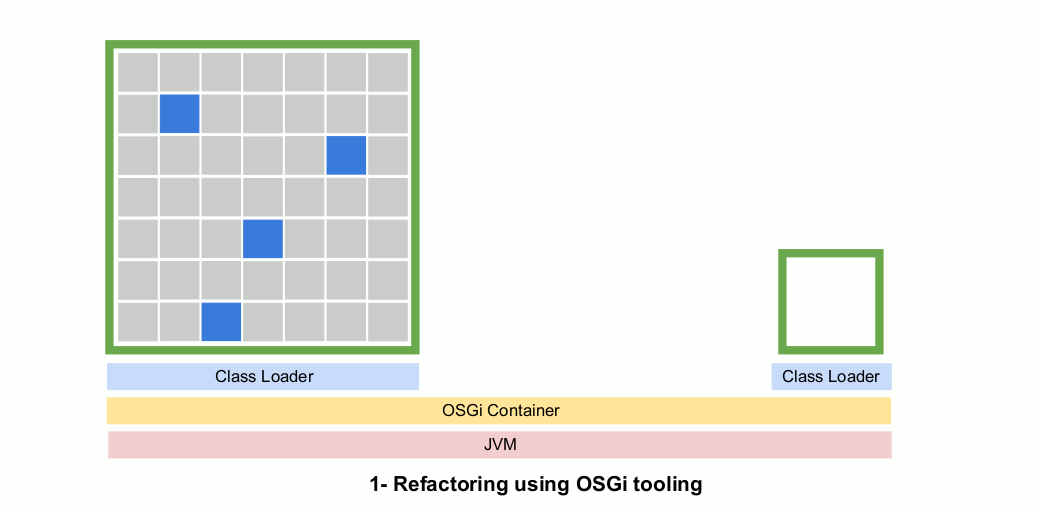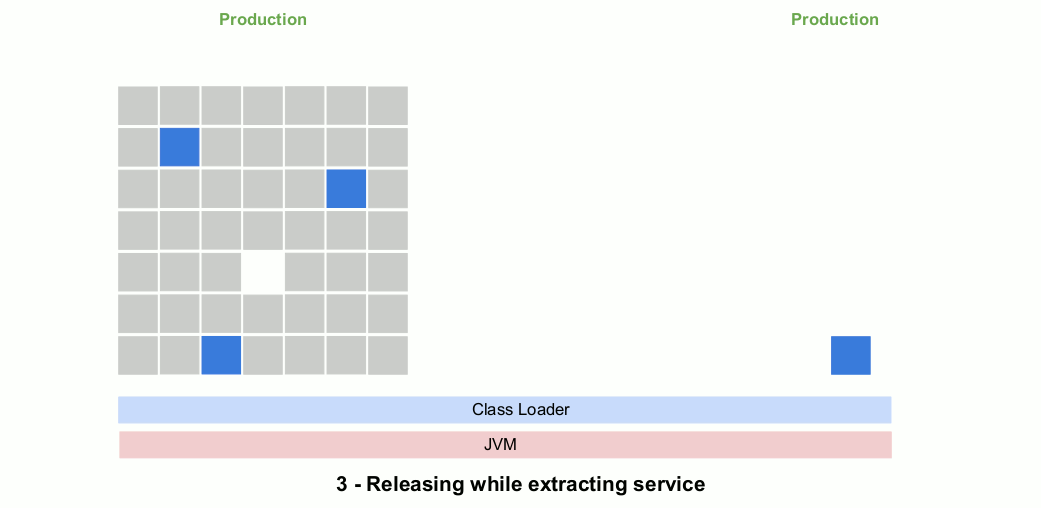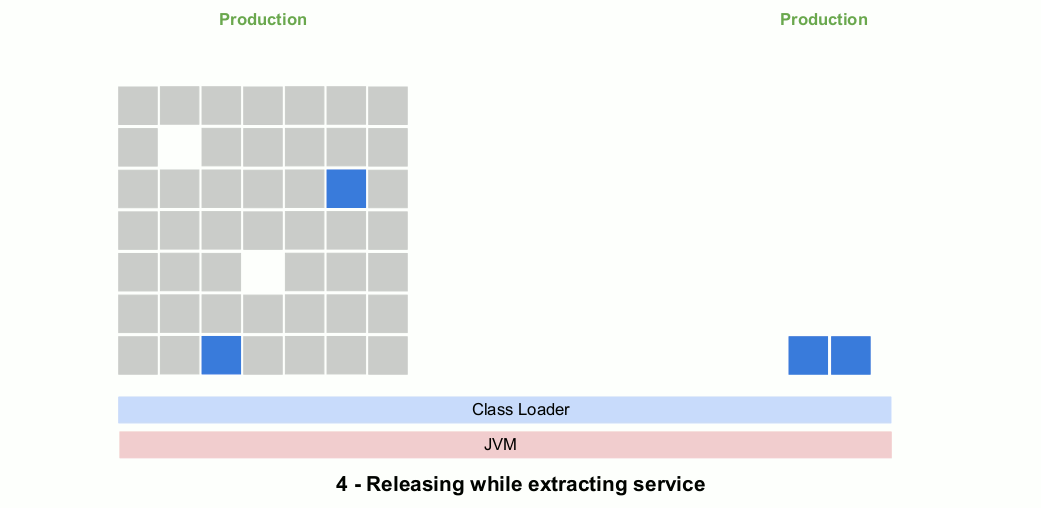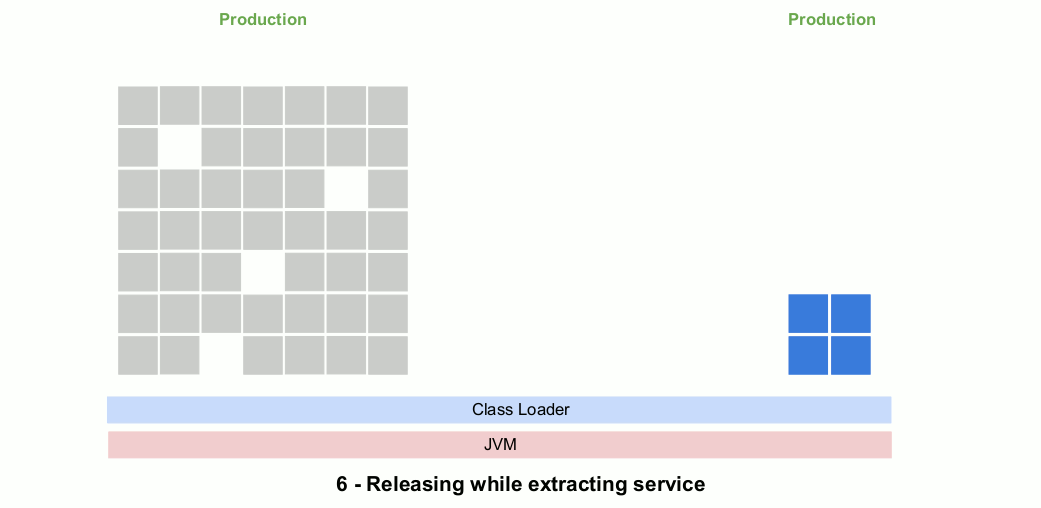
As the refactoring progresses, you can continually release the monolith to production without OSGi. The idea is to use OSGi inside the Eclipse IDE to leverage it’s advanced compiler and refactoring support and then deploy the Java application normally with the microservice packaged as a JAR running in the same class loader as the monolith.
One way to visualize this is that OSGi is providing a scaffolding during development that allows developers to safely do things they could not do otherwise. During deployment this scaffolding is removed and ignored.
In this animated gif you see a series of releases with the OSGi container removed. The extra OSGi metadata in the MANIFEST.MF file will have no effect if an OSGi container is not present. Note that the evolving microservice code is deployed to production during the entire extraction process.
Step 4: Deploy the microservice remotely
Once the microservice has been extracted it can then be deployed remotely and accessed through REST calls, events or whatever you like. It’s at this point that container and cloud-service technologies are introduced. Separating the refactoring operations from the deployment changes also minimizes the risk at each stage.
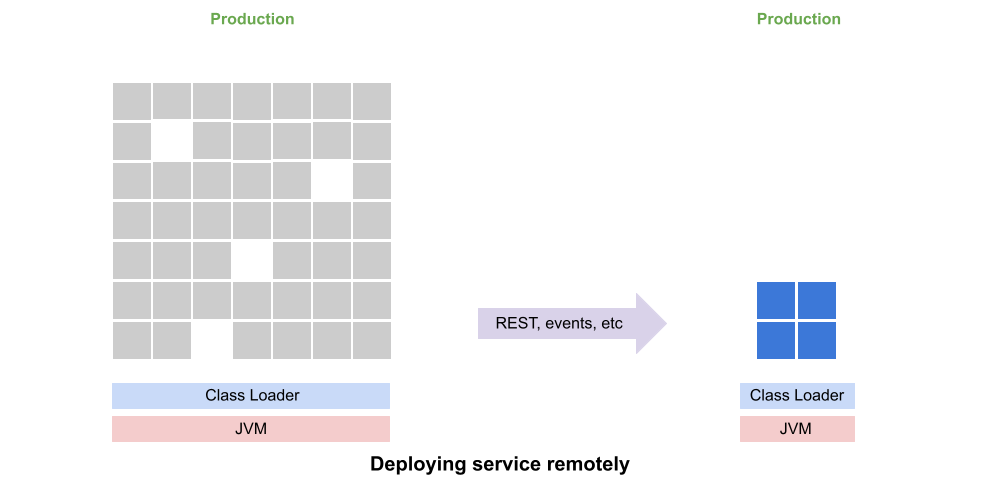
Canary testing is also possible with this approach, having the monolith gradually migrate from calling the local JAR to calling the remote service.
Wrapping up
For many years modular developers have been using and evolving OSGi-based tooling to break big pieces of code into small ones. While this experience wasn’t explicitly in the monolith to microservice domain, it really amounts to the same thing.
Setting up modular tooling in Eclipse is easy to do, as are the initial modifications to the monolith. Once that’s in place, you’ll have a development experience that is much more productive and less risky than is possible with traditional Java tooling.
If you’re interested in learning more about this approach or in discussing how it might be applied in your projects, why not schedule a free remote consultation and demo?